Nội dung như thế nào thì dễ được AI trích dẫn?
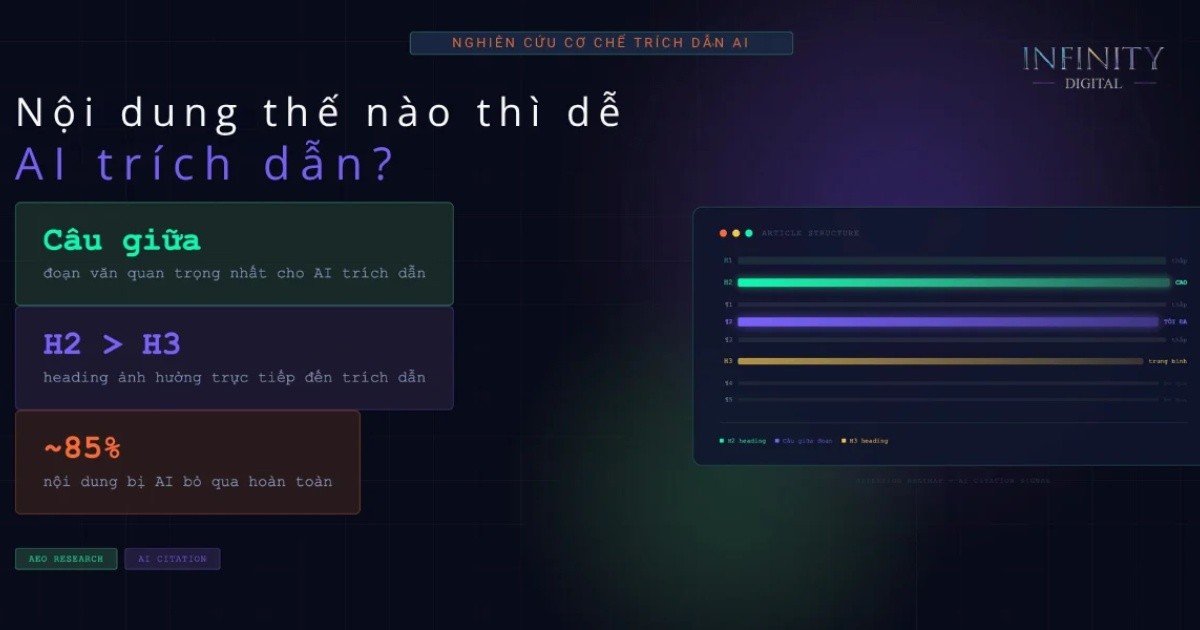
Table of Content
AI không đọc nội dung web theo cách viết truyền thống. Thay vì kiên nhẫn đọc từ đầu đến cuối như một độc giả, AI hoạt động giống một biên tập viên bận rộn: nó lướt nhanh, lấy thông tin quan trọng nhất từ phần đầu, rồi chỉ quay lại những đoạn nào chứa dữ liệu có giá trị cao.
Tóm tắt các điểm chính
Trong bài viết phân tích nghiên cứu mới từ Columbia University chúng ta biết “chiến lược phổ quát” đã được xác định: mô tả dài hơn, giọng thuyết phục cao, có yếu tố thổi phồng, không cần thêm thông tin thực chất mới. Chiến lược này hiệu quả xuyên danh mục, từ đồ gia dụng sang điện tử và thời trang.
Còn bài viết này sẽ dựa trên phân tích 18.012 trích dẫn đã xác minh từ Infinity để trả lời cho các bạn câu hỏi: Nội dung như thế nào sẽ được AI ưu tiên trích dẫn?
- 44,2% trích dẫn ChatGPT đến từ 30% đầu bài viết (mô hình “ski ramp”); 31,1% từ phần giữa; 24,7% từ phần cuối.
- AI đọc sâu từng đoạn: 53% trích dẫn lấy từ câu giữa đoạn văn, không phải câu đầu. AI tìm câu có “information gain” lớn nhất.
- Đáy 10% ở cuối gần như vô hình. Bên trong đoạn văn, 53% trích dẫn đến từ giữa đoạn, không phải câu đầu. Cho nên, AI đọc sâu, không chỉ quét câu mở.
- 5 đặc điểm nội dung được trích dẫn: ngôn ngữ khẳng định trực tiếp, cấu trúc hỏi – đáp, mật độ thực thể cao (~20%), giọng phân tích cân bằng (subjectivity ~0,47), và văn phong dễ đọc cấp doanh nghiệp (Flesch-Kincaid ~16).
- Viết cho AI khác viết cho SEO truyền thống. Hãy đưa tiên đề lên đầu, tuân theo cấu trúc BLUF (Bottom Line Up Front – kết luận đặt trước)
* Lưu ý: Nội dung bài viết không nhằm mục đích đưa ra checklist hoặc công thức cho việc tối ưu nội dung cho việc hiển thị AI.
ChatGPT trích dẫn từ vị trí nào trên trang web?
Trong nhiều năm, SEO viết “nội dung hướng dẫn toàn diện” được thiết kế để giữ người đọc trên trang: mở bài dài, kéo insight qua toàn bài, dàn trải đến CTA cuối cùng. Giờ đây, phong cách viết này không phù hợp cho AI visibility (mức độ hiển thị trên AI). Để được trích dẫn trong kỷ nguyên AI, bạn cần viết như một nhà báo, một biên tập viên.
Phân bổ trích dẫn theo mô hình “ski ramp”, dốc đều từ đầu đến cuối, là phát hiện trung tâm của nghiên cứu này. Từ 18.012 trích dẫn đã xác minh, Infinity nhận thấy ChatGPT phân bổ sự chú ý không đều trên trang web, với sự tập trung lệch hẳn về phần đầu.
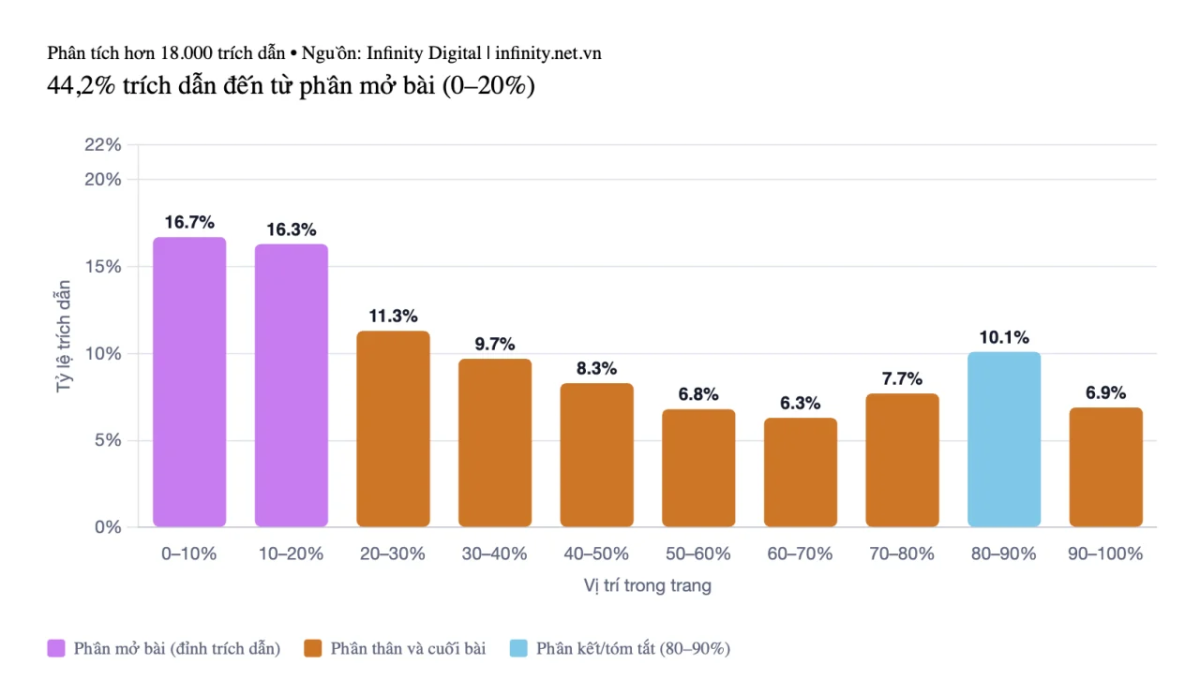
Biểu đồ phân bổ vị trí trích dẫn theo mô hình “ski ramp”, cho thấy 44,2% citation nằm ở 30% đầu nội dung.
Nguồn: Infinity
P-Value của phân tích này là 0,0 (p < 0,0001). Infinity chia 18.012 trích dẫn thành 4 batch ngẫu nhiên (randomized validation splits) để kiểm tra tính ổn định. Batch 1 phẳng hơn một chút, nhưng batch 2, 3 và 4 gần đồng nhất. Từ đây có thể kết luận mô hình “ski ramp” ổn định qua toàn bộ trích dẫn.
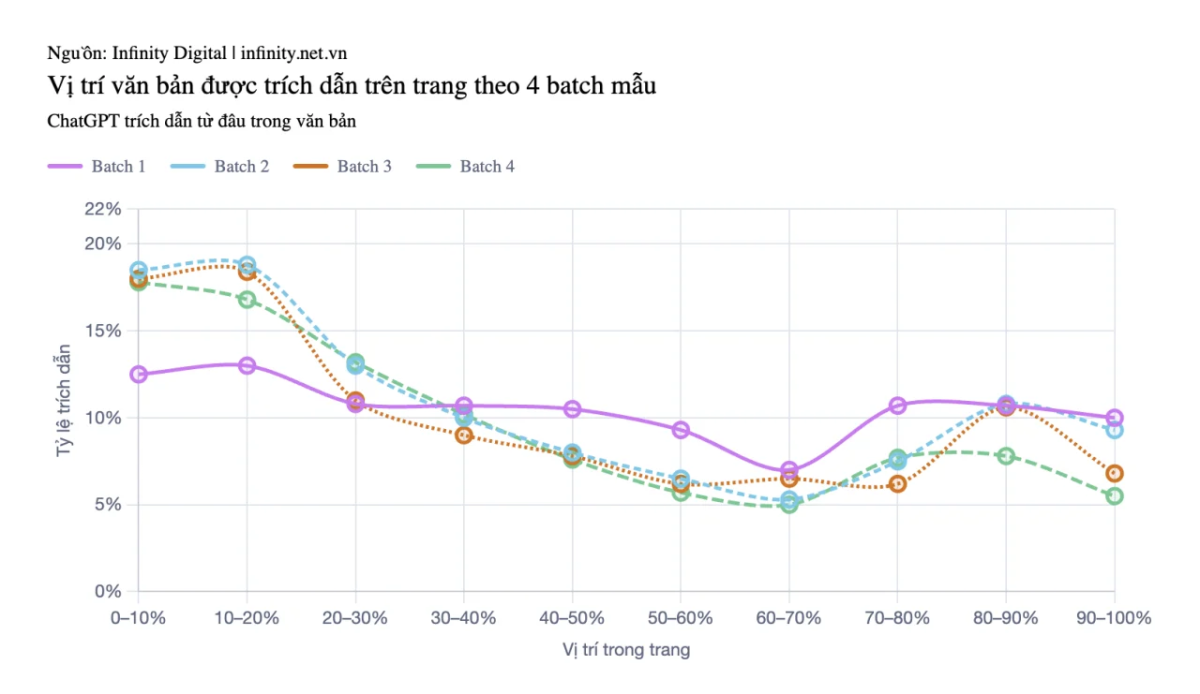
Biểu đồ so sánh 4 batch kiểm định chéo, cho thấy batch 2, 3, 4 gần như trùng khớp.
Nguồn: Infinity
3 giải thích cho mô hình “ski ramp”:
- Huấn luyện: LLM được huấn luyện trên báo chí và bài nghiên cứu học thuật, cả hai đều tuân theo cấu trúc BLUF. Model học rằng thông tin có “trọng số” cao nhất luôn nằm ở đầu bài.
- Hiệu quả: Dù model hiện đại đọc được tới 1 triệu token cho mỗi tương tác (~700.000-800.000 từ), chúng hướng tới thiết lập khung hiểu (frame) nhanh nhất có thể, rồi diễn giải mọi thứ khác qua khung đó.
- Ngoài lề: Thuộc về tư duy và văn hóa, AI được xây dựng từ văn bản dựa trên lối tư duy phương Tây (logic hình thức và tam đoạn luận Aristotle) đi từ tổng quát → cụ thể → kết luận.
AI chỉ đọc câu đầu mỗi đoạn hay đọc sâu hơn?
Mô hình “ski ramp” xác nhận một xu hướng vĩ mô rằng AI tập trung vào phần đầu trang. Nhưng ở cấp vi mô, bên trong từng đoạn văn, AI lại có hành vi khác.
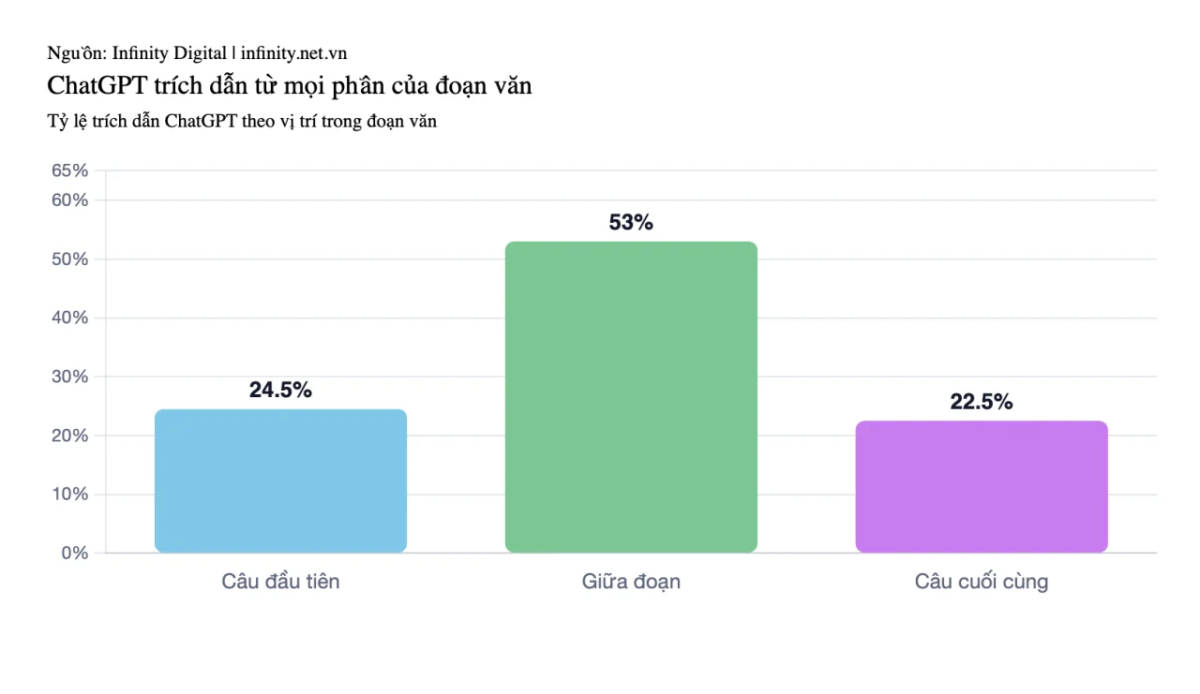
Biểu đồ phân bổ vị trí trích dẫn trong đoạn văn, 53% giữa đoạn, 24,5% câu đầu, 22,5% câu cuối.
Nguồn: Infinity
Cụ thể, 53% trích dẫn đến từ giữa đoạn văn. Nghĩa là ChatGPT không chỉ đọc câu đầu, nó đọc sâu và tìm câu có “information gain” cao nhất, câu chứa nhiều thực thể liên quan nhất và bổ sung nhiều thông tin mở rộng nhất, bất kể câu đó ở vị trí đầu, giữa hay cuối đoạn.
“Information gain” là điểm số đo lường những hiểu biết độc đáo về nội dung của bạn so với những gì người khác có.
Kết hợp hai phát hiện, chúng ta có thể hiểu rằng, cơ hội trích dẫn cao nhất nằm trong các đoạn văn thuộc 20% đầu trang, nhưng bên trong mỗi đoạn, người viết không cần ép câu trả lời vào câu đầu tiên. AI tìm câu giàu thông tin nhất, bất kể vị trí nào.
5 đặc điểm giúp nội dung được trích dẫn nhiều hơn
5 đặc điểm ngôn ngữ dưới đây sẽ giúp bạn phân biệt rõ ràng giữa nội dung được trích dẫn và nội dung bị bỏ qua. Sau khi xác định AI trích dẫn từ đâu trên trang, nghiên cứu chuyển sang phân tích “DNA ngôn ngữ” (linguistic DNA) của 11.022 trích dẫn để trả lời câu hỏi: Điều gì khiến một đoạn văn cụ thể được chọn thay vì đoạn khác?
5 đặc điểm đó là ngôn ngữ khẳng định, cấu trúc hỏi – đáp, mật độ thực thể cao, sắc thái cân bằng và văn phong chuyên nghiệp.
1. Ngôn ngữ khẳng định trực tiếp
Nội dung được trích dẫn có khả năng chứa ngôn ngữ khẳng định (“được định nghĩa là”, “đề cập đến”, “X là Y”) cao gấp gần 2 lần so với nội dung bị bỏ qua (36,2% so với 20,2%). Mối quan hệ giữa các khái niệm phải rõ ràng, dù không nhất thiết phải là định nghĩa từ điển.
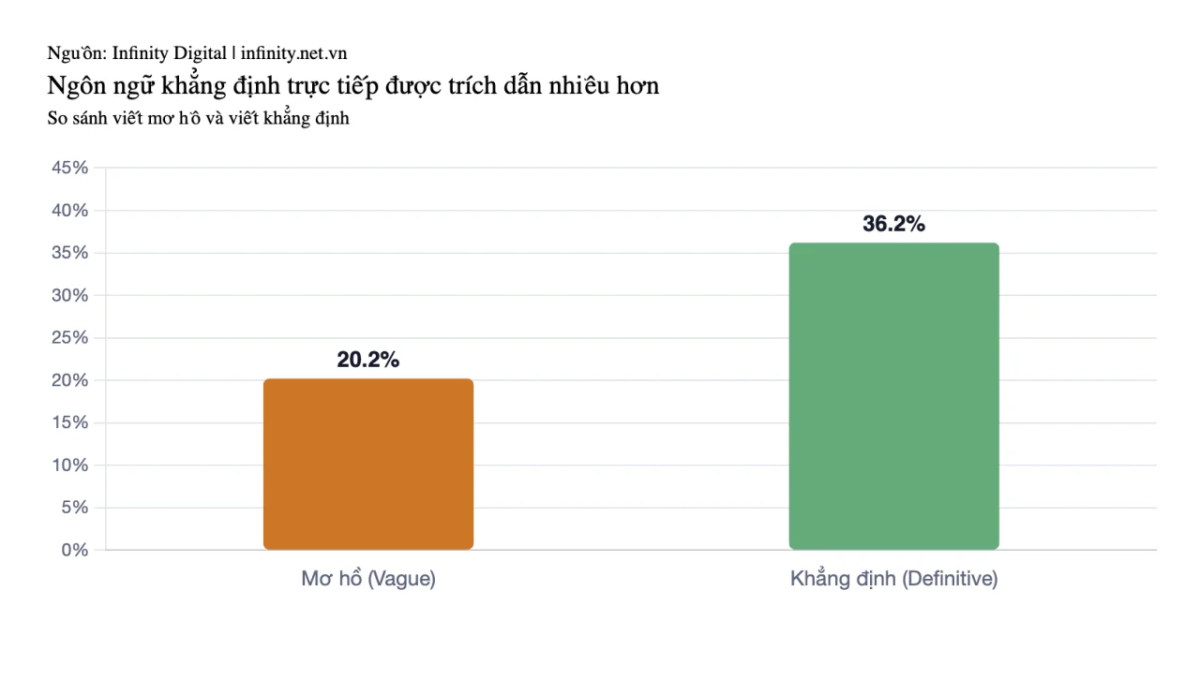
Biểu đồ so sánh tỷ lệ ngôn ngữ khẳng định giữa nội dung được trích dẫn (36,2%) và không được trích dẫn (20,2%).
Nguồn: Infinity
- Giải thích kỹ thuật: Trong cơ sở dữ liệu vector, từ “là” hoạt động như cầu nối mạnh giữa chủ thể và định nghĩa. Khi người dùng hỏi “X là gì?”, model tìm đường vector mạnh nhất, gần như luôn là cấu trúc “X là Y” trực tiếp. Model ưu tiên văn bản cho phép giải quyết truy vấn trong một câu (Zero-Shot) thay vì tổng hợp từ 5 đoạn.
- Ứng dụng thực tế rất rõ: Mở bài bằng câu khẳng định trực tiếp. Thay vì viết “Trong thế giới thay đổi nhanh chóng hiện nay, tự động hóa đang trở nên quan trọng…”, hãy viết “Tự động hóa demo là quy trình sử dụng phần mềm để…”. Câu đầu tiên phải thiết lập mối quan hệ rõ ràng giữa chủ thể và định nghĩa.
2. Cấu trúc hỏi – đáp
Nội dung được trích dẫn có khả năng chứa dấu hỏi cao gấp 2 lần so với nội dung bị bỏ qua (18,5% so với 9,5%). Viết dạng hội thoại ở đây nghĩa là sự phối hợp giữa câu hỏi và câu trả lời ngay sau đó.
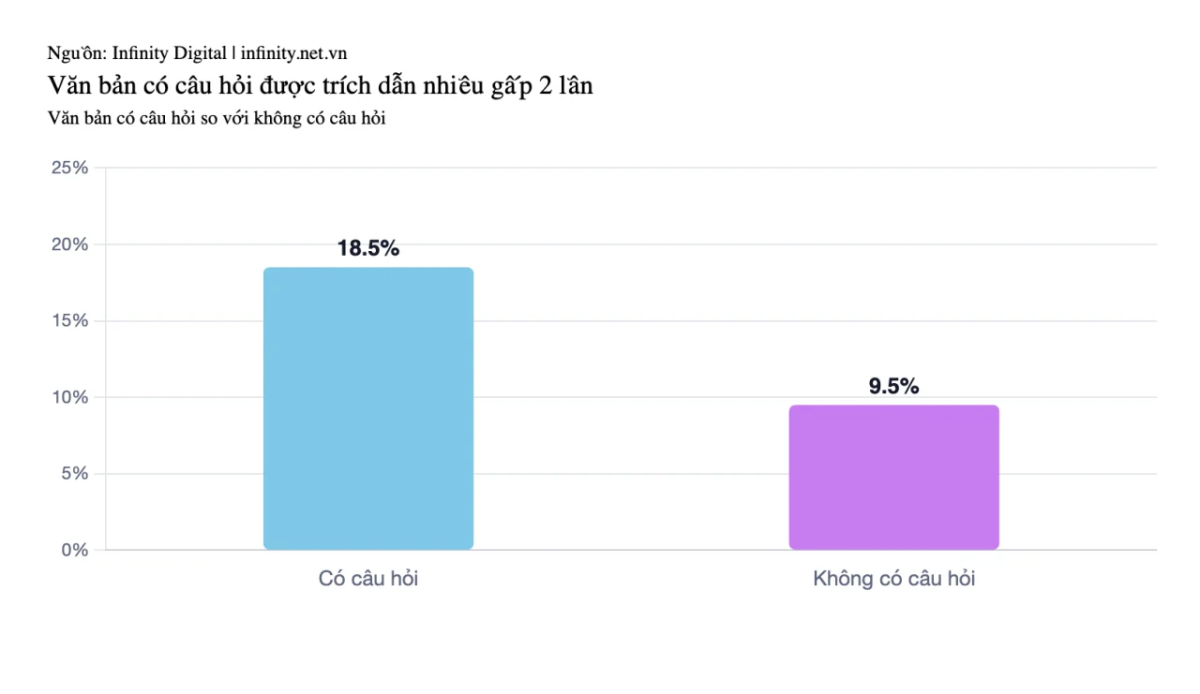
Biểu đồ so sánh tỷ lệ câu hỏi có trong nội dung được trích dẫn (18,5%) và không được trích dẫn (9,5%).
Nguồn: Infinity
78,4% trích dẫn có chứa câu hỏi đến từ Heading (thẻ H2). AI đang xử lý thẻ H2 như prompt của người dùng và đoạn văn ngay bên dưới như câu trả lời. Đây là cơ chế cốt lõi: Heading đóng vai trò truy vấn, nội dung dưới Heading đóng vai trò phản hồi.
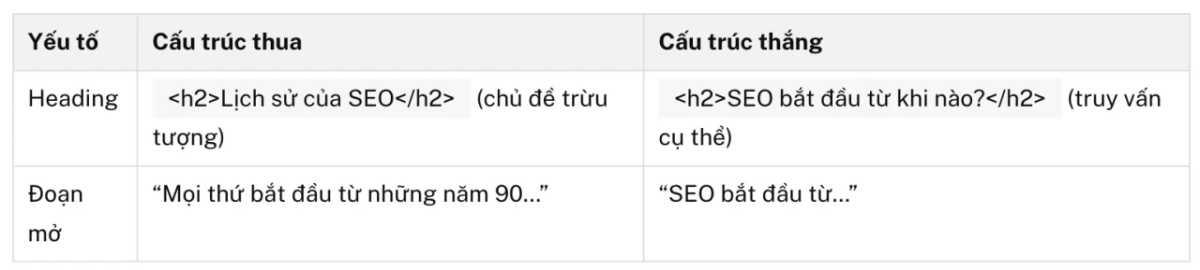
Ví dụ minh hoạ.
Nguồn: Infinity
“Cấu trúc thắng” ở bảng trên hoạt động bằng một kỹ thuật Infinity gọi là “entity echoing” (lặp lại thực thể). Heading hỏi về SEO, và từ đầu tiên trong câu trả lời cũng là SEO. Sự lặp lại này tạo tín hiệu rõ ràng cho mô hình rằng đoạn văn trực tiếp trả lời câu hỏi trong Heading.
3. Mật độ thực thể (entity density)
Nội dung được trích dẫn nhiều có mật độ thực thể trung bình 20,6%, cao gấp 3-4 lần so với văn bản tiếng Anh thông thường (5-8%). Mật độ thực thể đo lường tần suất xuất hiện của danh từ riêng trong văn bản, bao gồm tên thương hiệu, công cụ, người cụ thể, sản phẩm.
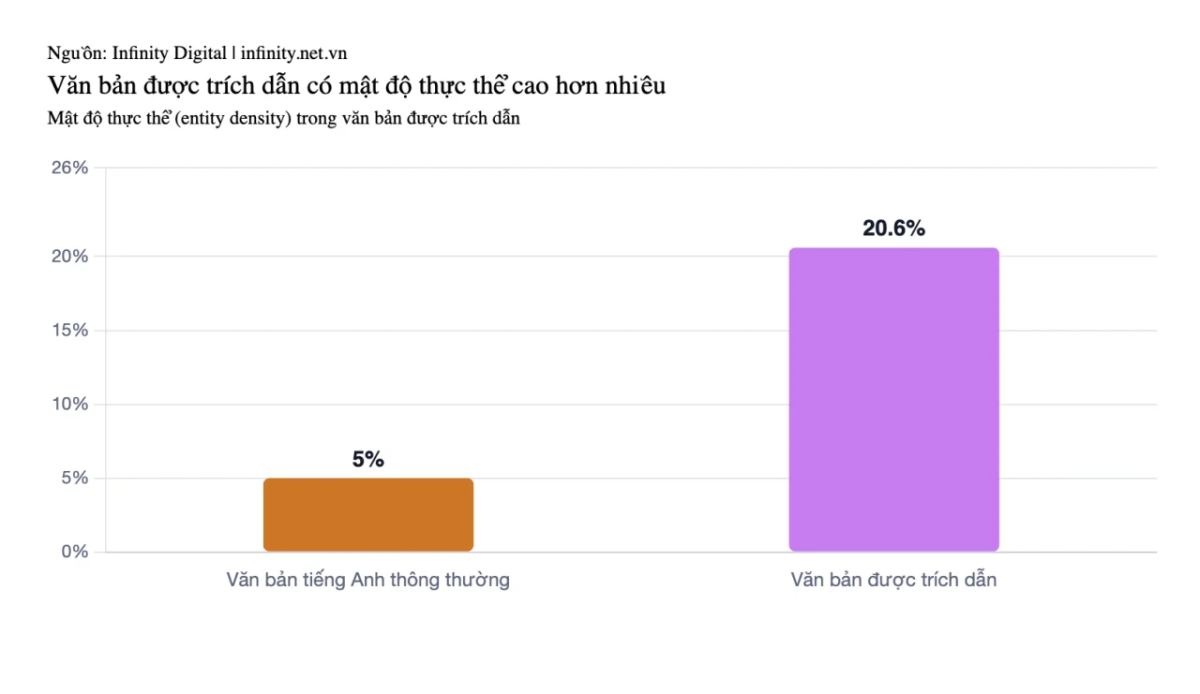
Biểu đồ so sánh entity density giữa nội dung thông thường (5-8%) và nội dung được trích dẫn cao (20,6%).
Nguồn: Infinity
Ngưỡng 5-8% là benchmark ngôn ngữ học lấy từ các kho ngữ liệu chuẩn như Brown Corpus (1 triệu từ tiếng Anh đại diện) và Penn Treebank (văn bản Wall Street Journal). Nội dung được AI trích dẫn vượt xa ngưỡng này.
Ví dụ, câu “Có nhiều công cụ tốt cho công việc này” có mật độ thực thể 0%. Câu “Các công cụ hàng đầu bao gồm Salesforce, HubSpot và Pipedrive” có mật độ khoảng 30%. LLM là hệ thống xác suất. Lời khuyên chung chung (“chọn công cụ phù hợp”) mang tính rủi ro và mơ hồ, nhưng một thực thể cụ thể (“chọn Salesforce”) có thể xác minh được. Mô hình ưu tiên các câu chứa “neo” (anchor) vì chúng làm giảm “perplexity” (độ nhầm lẫn) của câu trả lời.
Một câu có 3 thực thể mang nhiều “bit” thông tin hơn một câu có 0 thực thể. Vì vậy, nghiên cứu khuyến nghị đừng ngại đề cập tên cụ thể, kể cả tên đối thủ cạnh tranh. Trong bối cảnh AI citation, entity cụ thể là tín hiệu tin cậy, không phải rủi ro thương hiệu.
4. Giọng phân tích cân bằng
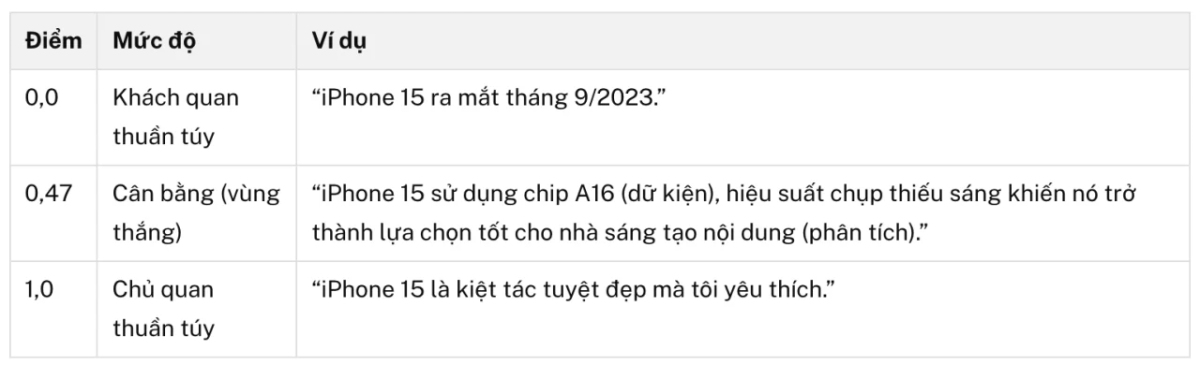
Nội dung được trích dẫn có điểm Subjectivity trung bình 0,47 trên thang 0,0-1,0. Subjectivity Score (điểm chủ quan) là chỉ số chuẩn trong Xử lý Ngôn ngữ Tự nhiên (NLP) đo lường mức độ ý kiến cá nhân, cảm xúc hoặc đánh giá chủ quan trong văn bản.
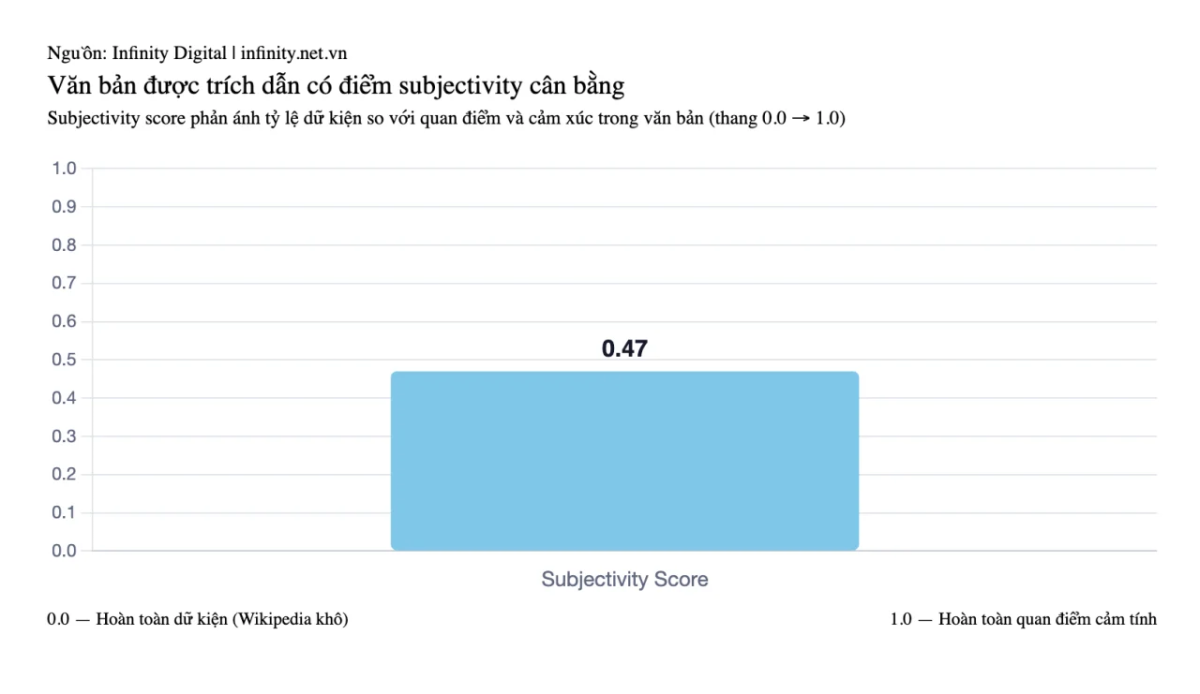
Văn bản được trích dẫn có Subjectivity Score cân bằng là 0,47.
Nguồn: Infinity
AI không muốn văn bản khô khan kiểu Wikipedia (0,1), cũng không muốn ý kiến cảm tính (0,9). Vùng tối ưu nằm ở khoảng 0,47, nơi Infinity gọi là “giọng phân tích” (analyst voice). Đây là phong cách giải thích một dữ kiện ứng dụng thế nào trong thực tế, thay vì chỉ trình bày con số rồi để đấy.
Ví dụ minh hoạ.
Nguồn: Infinity
Cấu trúc lý tưởng cho mỗi đoạn văn là một dữ kiện có thể xác minh, kết hợp với một câu phân tích hoặc nhận định ứng dụng. Không phải toàn bộ là số liệu. Không phải toàn bộ là ý kiến.
5. Văn phong dễ đọc cấp doanh nghiệp
Văn phong chuyên nghiệp cấp doanh nghiệp (business-grade writing) tương đương lối viết của The Economist hay Harvard Business Review được trích dẫn nhiều hơn. Nội dung “thắng” có điểm Flesch-Kincaid (FK) trung bình 16 (cấp đại học), trong khi nội dung “thua” đạt 19,1 (cấp nghiên cứu sinh, PhD).
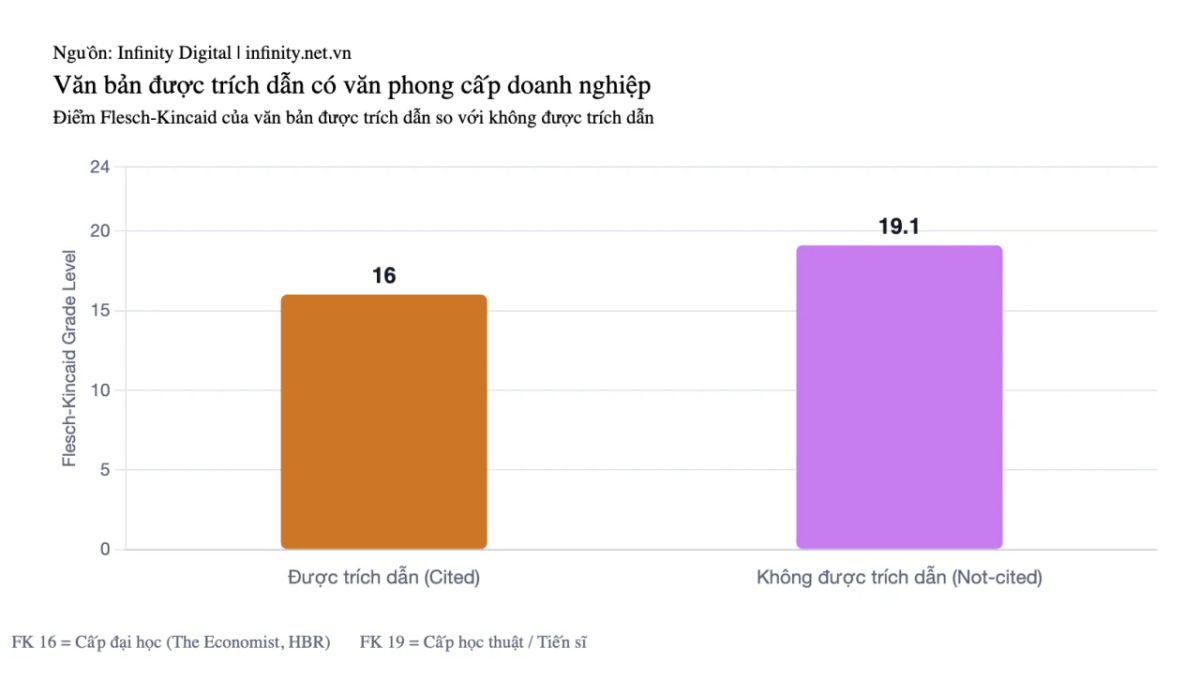
Biểu đồ so sánh Flesch-Kincaid score giữa nội dung thắng (16) và thua (19,1).
Nguồn: Infinity
Kể cả với chủ đề khó, sự phức tạp trong cách viết có thể gây hại. Điểm FK 19 đồng nghĩa câu dài, quanh co, chứa nhiều thuật ngữ đa âm tiết. AI ưu tiên cấu trúc “Chủ ngữ – Động từ – Tân ngữ” rõ ràng với câu ngắn đến trung bình, vì chúng dễ trích xuất dữ kiện hơn.
Phát hiện này bác bỏ quan niệm rằng AI “thưởng” cho nội dung viết đơn giản hóa quá mức (dumbing down). Ngưỡng FK 16 là cấp đại học, không phải cấp phổ thông. AI thưởng cho sự rõ ràng ở cấp chuyên nghiệp, không phải sự đơn giản ở cấp phổ thông.
Phát hiện này thay đổi cách viết nội dung thế nào?
Mô hình “ski ramp” đo lường sự lệch pha giữa lối viết kể chuyện (narrative writing) và truy xuất thông tin (information retrieval). Thuật toán diễn giải kỹ thuật “hé lộ từ từ” như thiếu tự tin. Nó ưu tiên phân loại thực thể và dữ kiện ngay lập tức.
Nội dung có AI visibility cao hoạt động giống bản tóm tắt có cấu trúc (structured briefing) hơn là câu chuyện.
Điều này áp đặt việc nội dung minh bạch, có rõ ràng, có căn cứ có thể kiểm chứng lên người viết nội dung. Nội dung “thắng” trong bộ dữ liệu này dựa vào từ vựng cấp doanh nghiệp và mật độ thực thể cao. Nhưng khoảng cách giữa sở thích của người đọc và yêu cầu của máy đang thu hẹp. Trong các bài viết doanh nghiệp, người đọc cũng quét tìm insight. Do đó, cách viết đặt kết luận lên đầu có thể phục vụ cả cấu trúc thuật toán lẫn thời gian hạn chế của người đọc.
Đây là nền tảng thực hành cho tối ưu AI search: cấu trúc nội dung quyết định tỷ lệ trích dẫn nhiều hơn chiều sâu nội dung ở cuối bài. Topical Authority (Thẩm quyền chủ đề) cung cấp chiều sâu, nhưng chiều sâu đó cần được đặt đúng vị trí 20% đầu trang để AI trích dẫn.
* Nguồn: Infinity